Node-splitting model for testing consistency at the treatment-level
nma.nodesplit.RdSplits contributions for a given set of treatment comparisons into direct and indirect evidence. A discrepancy between the two suggests that the consistency assumption required for NMA (and subsequently MBNMA) may violated.
nma.nodesplit(
network,
likelihood = NULL,
link = NULL,
method = "common",
comparisons = NULL,
drop.discon = TRUE,
...
)
# S3 method for class 'nma.nodesplit'
plot(x, plot.type = NULL, ...)Arguments
- network
An object of class
mbnma.network.- likelihood
A string indicating the likelihood to use in the model. Can take either
"binomial","normal"or"poisson". If left asNULLthe likelihood will be inferred from the data.- link
A string indicating the link function to use in the model. Can take any link function defined within JAGS (e.g.
"logit","log","probit","cloglog"), be assigned the value"identity"for an identity link function, or be assigned the value"smd"for modelling Standardised Mean Differences using an identity link function. If left asNULLthe link function will be automatically assigned based on the likelihood.- method
Can take either
"common"or"random"to indicate whether relative effects should be modelled with between-study heterogeneity or not (see details).- comparisons
A matrix specifying the comparisons to be split (one row per comparison). The matrix must have two columns indicating each treatment for each comparison. Values can either be character (corresponding to the treatment names given in
network) or numeric (corresponding to treatment codes within thenetwork- note that these may change ifdrop.discon = TRUE).- drop.discon
A boolean object that indicates whether to drop treatments that are disconnected at the treatment level. Default is
TRUE. If set toFALSEthen this could lead to identification of nodesplit comparisons that are not connected to the network reference treatment, or lead to errors in running the nodesplit models, though it can be useful for error checking.- ...
Arguments to be sent to
ggplot2::ggplot()- x
An object of
class("nma.nodesplit")- plot.type
A character string that can take the value of
"forest"to plot only forest plots,"density"to plot only density plots, or left asNULL(the default) to plot both types of plot.
Value
Plots the desired graph(s) and returns an object (or list of object if
plot.type=NULL) of class(c("gg", "ggplot"))
Details
The S3 method plot() on an nma.nodesplit object generates either
forest plots of posterior medians and 95\% credible intervals, or density plots
of posterior densities for direct and indirect evidence.
Methods (by generic)
plot(nma.nodesplit): Plot outputs from treatment-level nodesplit models
Examples
# \donttest{
# Using the triptans data
network <- mbnma.network(triptans)
#> Values for `agent` with dose = 0 have been recoded to `Placebo`
#> agent is being recoded to enforce sequential numbering
split <- nma.nodesplit(network, likelihood = "binomial", link="logit",
method="common")
#>
|
| | 0%
|
|=== | 4%
|
|===== | 8%
|
|======== | 12%
|
|=========== | 15%
#>
|
|============= | 19%
#>
|
|================ | 23%
|
|=================== | 27%
|
|====================== | 31%
|
|======================== | 35%
|
|=========================== | 38%
|
|============================== | 42%
#>
|
|================================ | 46%
|
|=================================== | 50%
|
|====================================== | 54%
#>
|
|======================================== | 58%
|
|=========================================== | 62%
|
|============================================== | 65%
|
|================================================ | 69%
|
|=================================================== | 73%
|
|====================================================== | 77%
|
|========================================================= | 81%
#>
|
|=========================================================== | 85%
#>
|
|============================================================== | 88%
#>
|
|================================================================= | 92%
#>
|
|=================================================================== | 96%
#>
|
|======================================================================| 100%
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 182
#> Unobserved stochastic nodes: 92
#> Total graph size: 3436
#>
#> Initializing model
#>
#> [1] "Calculating nodesplit for: zolmitriptan_1 vs almotriptan_1"
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 180
#> Unobserved stochastic nodes: 91
#> Total graph size: 3397
#>
#> Initializing model
#>
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 182
#> Unobserved stochastic nodes: 323
#> Total graph size: 3641
#>
#> Initializing model
#>
#> [1] "Calculating nodesplit for: rizatriptan_1 vs sumatriptan_1"
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 180
#> Unobserved stochastic nodes: 91
#> Total graph size: 3395
#>
#> Initializing model
#>
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 182
#> Unobserved stochastic nodes: 323
#> Total graph size: 3641
#>
#> Initializing model
#>
#> [1] "Calculating nodesplit for: almotriptan_1 vs sumatriptan_1"
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 180
#> Unobserved stochastic nodes: 91
#> Total graph size: 3395
#>
#> Initializing model
#>
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 182
#> Unobserved stochastic nodes: 323
#> Total graph size: 3641
#>
#> Initializing model
#>
#> [1] "Calculating nodesplit for: rizatriptan_0.5 vs sumatriptan_0.5"
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 180
#> Unobserved stochastic nodes: 91
#> Total graph size: 3396
#>
#> Initializing model
#>
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 182
#> Unobserved stochastic nodes: 323
#> Total graph size: 3641
#>
#> Initializing model
#>
#### To perform nodesplit on selected comparisons ####
# Check for closed loops of treatments with independent evidence sources
loops <- inconsistency.loops(network$data.ab)
#>
|
| | 0%
|
|=== | 4%
|
|===== | 8%
|
|======== | 12%
|
|=========== | 15%
#>
|
|============= | 19%
#>
|
|================ | 23%
|
|=================== | 27%
|
|====================== | 31%
|
|======================== | 35%
|
|=========================== | 38%
|
|============================== | 42%
#>
|
|================================ | 46%
|
|=================================== | 50%
|
|====================================== | 54%
#>
|
|======================================== | 58%
|
|=========================================== | 62%
|
|============================================== | 65%
|
|================================================ | 69%
|
|=================================================== | 73%
|
|====================================================== | 77%
|
|========================================================= | 81%
#>
|
|=========================================================== | 85%
#>
|
|============================================================== | 88%
#>
|
|================================================================= | 92%
#>
|
|=================================================================== | 96%
#>
|
|======================================================================| 100%
# This...
single.split <- nma.nodesplit(network, likelihood = "binomial", link="logit",
method="random", comparisons=rbind(c("sumatriptan_1", "almotriptan_1")))
#>
|
| | 0%
|
|=== | 4%
|
|===== | 8%
|
|======== | 12%
|
|=========== | 15%
#>
|
|============= | 19%
#>
|
|================ | 23%
|
|=================== | 27%
|
|====================== | 31%
|
|======================== | 35%
|
|=========================== | 38%
|
|============================== | 42%
#>
|
|================================ | 46%
|
|=================================== | 50%
|
|====================================== | 54%
#>
|
|======================================== | 58%
|
|=========================================== | 62%
|
|============================================== | 65%
|
|================================================ | 69%
|
|=================================================== | 73%
|
|====================================================== | 77%
|
|========================================================= | 81%
#>
|
|=========================================================== | 85%
#>
|
|============================================================== | 88%
#>
|
|================================================================= | 92%
#>
|
|=================================================================== | 96%
#>
|
|======================================================================| 100%
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 182
#> Unobserved stochastic nodes: 205
#> Total graph size: 3979
#>
#> Initializing model
#>
#> [1] "Calculating nodesplit for: almotriptan_1 vs sumatriptan_1"
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 180
#> Unobserved stochastic nodes: 203
#> Total graph size: 3934
#>
#> Initializing model
#>
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 182
#> Unobserved stochastic nodes: 436
#> Total graph size: 4071
#>
#> Initializing model
#>
#...is the same as...
single.split <- nma.nodesplit(network, likelihood = "binomial", link="logit",
method="random", comparisons=rbind(c(6, 12)))
#>
|
| | 0%
|
|=== | 4%
|
|===== | 8%
|
|======== | 12%
|
|=========== | 15%
#>
|
|============= | 19%
#>
|
|================ | 23%
|
|=================== | 27%
|
|====================== | 31%
|
|======================== | 35%
|
|=========================== | 38%
|
|============================== | 42%
#>
|
|================================ | 46%
|
|=================================== | 50%
|
|====================================== | 54%
#>
|
|======================================== | 58%
|
|=========================================== | 62%
|
|============================================== | 65%
|
|================================================ | 69%
|
|=================================================== | 73%
|
|====================================================== | 77%
|
|========================================================= | 81%
#>
|
|=========================================================== | 85%
#>
|
|============================================================== | 88%
#>
|
|================================================================= | 92%
#>
|
|=================================================================== | 96%
#>
|
|======================================================================| 100%
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 182
#> Unobserved stochastic nodes: 205
#> Total graph size: 3979
#>
#> Initializing model
#>
#> [1] "Calculating nodesplit for: almotriptan_1 vs sumatriptan_1"
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 180
#> Unobserved stochastic nodes: 203
#> Total graph size: 3934
#>
#> Initializing model
#>
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 182
#> Unobserved stochastic nodes: 436
#> Total graph size: 4071
#>
#> Initializing model
#>
# Plot results
plot(split, plot.type="density") # Plot density plots of posterior densities
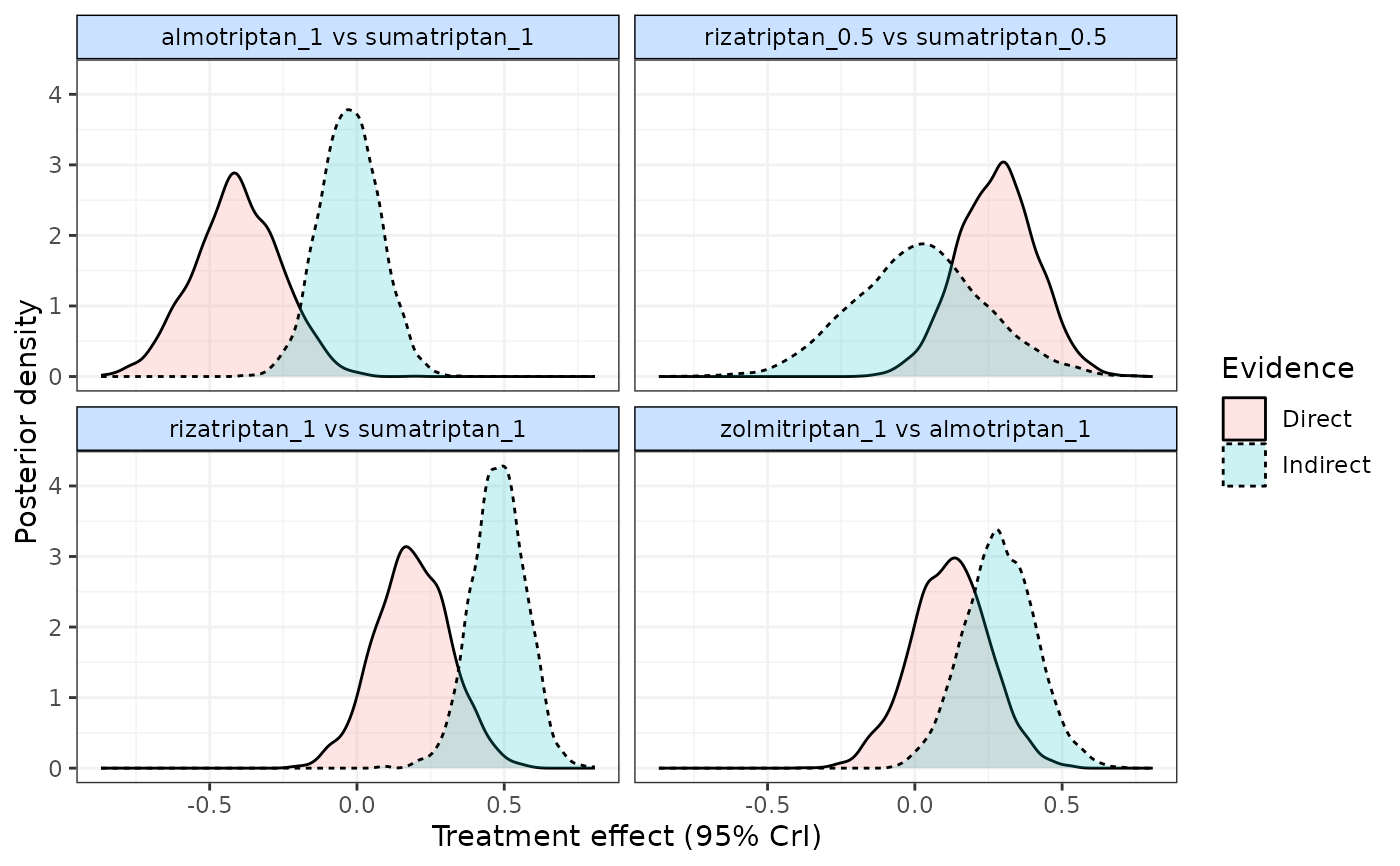 plot(split, plot.type="forest") # Plot forest plots of direct and indirect evidence
plot(split, plot.type="forest") # Plot forest plots of direct and indirect evidence
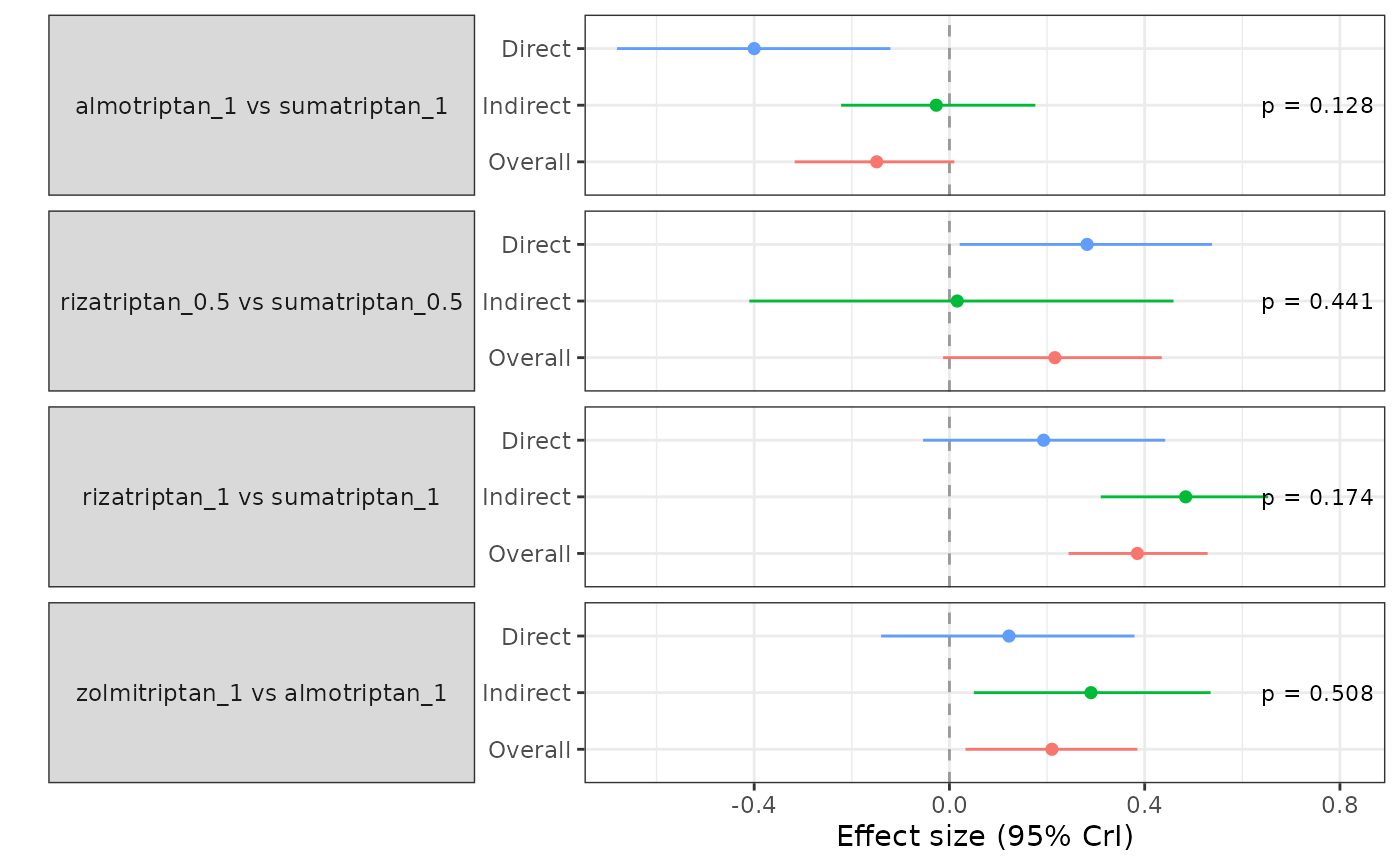 # Print and summarise results
print(split)
#> ========================================
#> Node-splitting analysis of inconsistency
#> ========================================
#> |Comparison | p-value| Median| 2.5%| 97.5%|
#> |:----------------------------------|-------:|------:|------:|------:|
#> |zolmitriptan_1 vs almotriptan_1 | 0.508| | | |
#> |-> direct | | 0.122| -0.140| 0.379|
#> |-> indirect | | 0.290| 0.050| 0.535|
#> |-> MBNMA | | 0.210| 0.033| 0.385|
#> | | | | | |
#> |rizatriptan_1 vs sumatriptan_1 | 0.174| | | |
#> |-> direct | | 0.193| -0.054| 0.442|
#> |-> indirect | | 0.484| 0.310| 0.653|
#> |-> MBNMA | | 0.385| 0.244| 0.529|
#> | | | | | |
#> |almotriptan_1 vs sumatriptan_1 | 0.128| | | |
#> |-> direct | | -0.400| -0.681| -0.121|
#> |-> indirect | | -0.027| -0.222| 0.176|
#> |-> MBNMA | | -0.149| -0.317| 0.010|
#> | | | | | |
#> |rizatriptan_0.5 vs sumatriptan_0.5 | 0.441| | | |
#> |-> direct | | 0.282| 0.021| 0.538|
#> |-> indirect | | 0.016| -0.410| 0.459|
#> |-> MBNMA | | 0.216| -0.013| 0.435|
#> | | | | | |
summary(split) # Generate a data frame of summary results
#> Comparison Evidence Median 2.5% 97.5% p.value
#> 1 zolmitriptan_1 vs almotriptan_1 Direct 0.122 -0.140 0.379 0.508
#> 2 zolmitriptan_1 vs almotriptan_1 Indirect 0.290 0.050 0.535 0.508
#> 3 zolmitriptan_1 vs almotriptan_1 NMA 0.210 0.033 0.385 0.508
#> 4 rizatriptan_1 vs sumatriptan_1 Direct 0.193 -0.054 0.442 0.174
#> 5 rizatriptan_1 vs sumatriptan_1 Indirect 0.484 0.310 0.653 0.174
#> 6 rizatriptan_1 vs sumatriptan_1 NMA 0.385 0.244 0.529 0.174
#> 7 almotriptan_1 vs sumatriptan_1 Direct -0.400 -0.681 -0.121 0.128
#> 8 almotriptan_1 vs sumatriptan_1 Indirect -0.027 -0.222 0.176 0.128
#> 9 almotriptan_1 vs sumatriptan_1 NMA -0.149 -0.317 0.010 0.128
#> 10 rizatriptan_0.5 vs sumatriptan_0.5 Direct 0.282 0.021 0.538 0.441
#> 11 rizatriptan_0.5 vs sumatriptan_0.5 Indirect 0.016 -0.410 0.459 0.441
#> 12 rizatriptan_0.5 vs sumatriptan_0.5 NMA 0.216 -0.013 0.435 0.441
# }
# Print and summarise results
print(split)
#> ========================================
#> Node-splitting analysis of inconsistency
#> ========================================
#> |Comparison | p-value| Median| 2.5%| 97.5%|
#> |:----------------------------------|-------:|------:|------:|------:|
#> |zolmitriptan_1 vs almotriptan_1 | 0.508| | | |
#> |-> direct | | 0.122| -0.140| 0.379|
#> |-> indirect | | 0.290| 0.050| 0.535|
#> |-> MBNMA | | 0.210| 0.033| 0.385|
#> | | | | | |
#> |rizatriptan_1 vs sumatriptan_1 | 0.174| | | |
#> |-> direct | | 0.193| -0.054| 0.442|
#> |-> indirect | | 0.484| 0.310| 0.653|
#> |-> MBNMA | | 0.385| 0.244| 0.529|
#> | | | | | |
#> |almotriptan_1 vs sumatriptan_1 | 0.128| | | |
#> |-> direct | | -0.400| -0.681| -0.121|
#> |-> indirect | | -0.027| -0.222| 0.176|
#> |-> MBNMA | | -0.149| -0.317| 0.010|
#> | | | | | |
#> |rizatriptan_0.5 vs sumatriptan_0.5 | 0.441| | | |
#> |-> direct | | 0.282| 0.021| 0.538|
#> |-> indirect | | 0.016| -0.410| 0.459|
#> |-> MBNMA | | 0.216| -0.013| 0.435|
#> | | | | | |
summary(split) # Generate a data frame of summary results
#> Comparison Evidence Median 2.5% 97.5% p.value
#> 1 zolmitriptan_1 vs almotriptan_1 Direct 0.122 -0.140 0.379 0.508
#> 2 zolmitriptan_1 vs almotriptan_1 Indirect 0.290 0.050 0.535 0.508
#> 3 zolmitriptan_1 vs almotriptan_1 NMA 0.210 0.033 0.385 0.508
#> 4 rizatriptan_1 vs sumatriptan_1 Direct 0.193 -0.054 0.442 0.174
#> 5 rizatriptan_1 vs sumatriptan_1 Indirect 0.484 0.310 0.653 0.174
#> 6 rizatriptan_1 vs sumatriptan_1 NMA 0.385 0.244 0.529 0.174
#> 7 almotriptan_1 vs sumatriptan_1 Direct -0.400 -0.681 -0.121 0.128
#> 8 almotriptan_1 vs sumatriptan_1 Indirect -0.027 -0.222 0.176 0.128
#> 9 almotriptan_1 vs sumatriptan_1 NMA -0.149 -0.317 0.010 0.128
#> 10 rizatriptan_0.5 vs sumatriptan_0.5 Direct 0.282 0.021 0.538 0.441
#> 11 rizatriptan_0.5 vs sumatriptan_0.5 Indirect 0.016 -0.410 0.459 0.441
#> 12 rizatriptan_0.5 vs sumatriptan_0.5 NMA 0.216 -0.013 0.435 0.441
# }